深入理解Go调度器:初识GMP模型(一)
认识GMP模型
本文主要介绍当前runtime中调度器的 GMP 模型的基本概念,建立起对调度器相对粗框架的认识。理解调度器需要先了解下 GMP 模型中三个组件的关系和定义:
- G:Goroutine,即 Go 协程,就是程序中使用
go关键字运行的函数 - M:Machine,代表系统线程,M 是 runtime 中的一个对象,每创建一个 M 的同时创建一个系统线程,并与 M 进行绑定
- P:Processer,代表处理器,这是一层抽象的概念【稍后会讲到为什么需要引入这一层】
G 运行需要与 M 绑定,M 需要与 P 绑定。
关于 P & M 的数量问题。
- P 的数量由用户决定,程序启动时环境变量
$GOMAXPROCS或者 runtime 的GOMAXPROCS()方法决定。这意味着在程序的整个生命周期都最多只有$GOMAXPROCS个 G 在同时运行。 - M 的数量由 Go 语言本身决定。尽管
runtime/deBug中SetMaxThread可以设置 M 的数量,默认为10000,但通常操作系统层面不太可能让创建这么多。
其次,任意一个时刻,只有一个 M 能够运行一个P,所以可以认为 P 和 M是一对一的绑定关系。但是,M 在需要的时候,调度器可以创建更多,比如某些 M 被阻塞。
下面是G/M/P三个组件的整体关系:
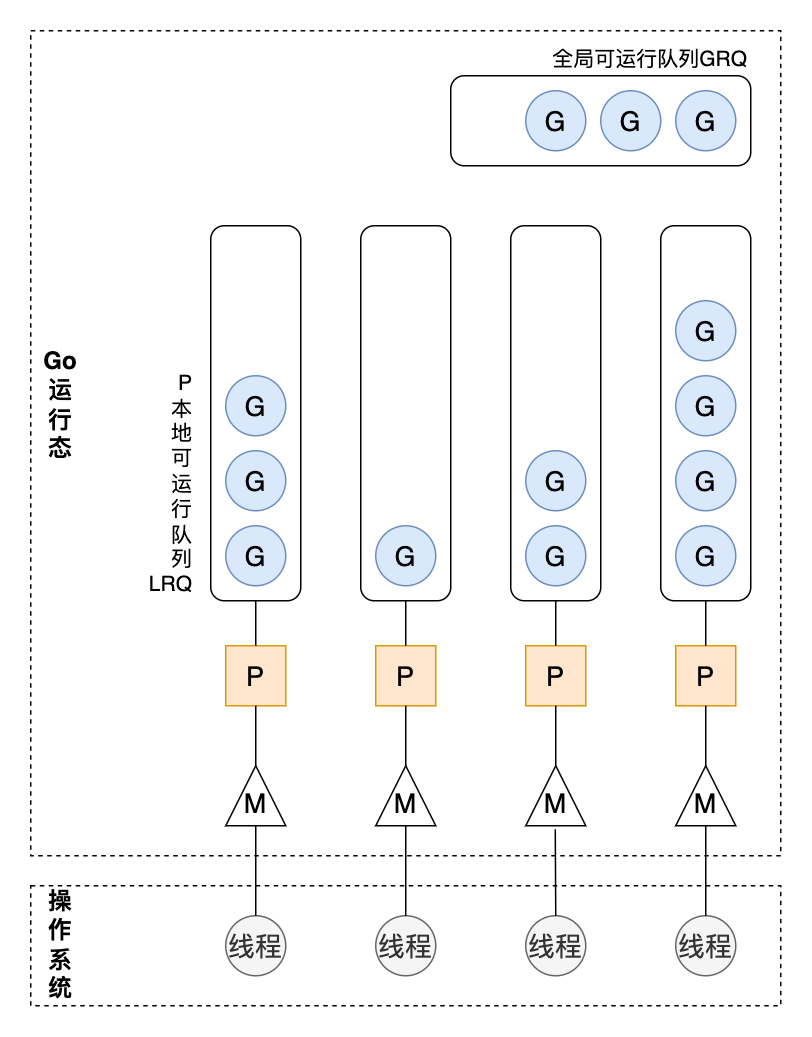
G,M,P都解释了,还有两个比较重要的结构没有解释:
- 全局可运行队列(GRQ):存储全局可运行的G,都说全局了,所以访问它肯定需要加锁。这里的加锁是针对 M 说的,因为某些情况下,M 可能会从 GRQ 中获取 G 来执行。
- 本地可运行队列(LRQ):存储 P 上可以可运行的G,既然本地了,所以不用加锁,M 直接从绑定的 P 的 LRQ 中获取 G 来执行。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中。最多有
GOMAXPROCS个。
注意,在 Go 的早期版本中,并没有 P 这个结构,M 必须从一个全局队列中获取要运行的 G,当并发量很大时,锁就成了瓶颈。所以,后来大神 Dmitry Vyokov 在调度器的实现中增加了 P 结构,每个 P 维护一个自己的 G 队列,解决了全局锁的问题。详见:https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit
调度的目标
For scheduling goroutines onto kernel threads.

翻译一下就是,调度 goroutine 到系统线程:
如果让我来说,更直观的目标有三个:
- 目标1:尽可能地不要让 CPU 闲着
- 目标2:尽可能地运行更多的 G (代码)
- 目标3:尽量最小化 Go 协程切换所带来的开销
调度机制
接下来,看两个比较重要的调度机制。
- 窃取机制
- 交接机制
work stealing mechanism(偷窃机制)
前面讲到,G 最终要在 M 上执行,且 M 优先从与之绑定的 P 的 LRQ 中取出 G 来执行,但如果 LRQ 为空,那么 M 会从 GRQ 队列中取出 G 并执行。(还有这么多活没有认领,当然要主动在组织分担啦。)
但是,如果GRQ 也为空呢?M 则会尝试从其他 P 的 LRQ 中 ”偷“ 一些 G 来执行。这就是 work-steal 机制。
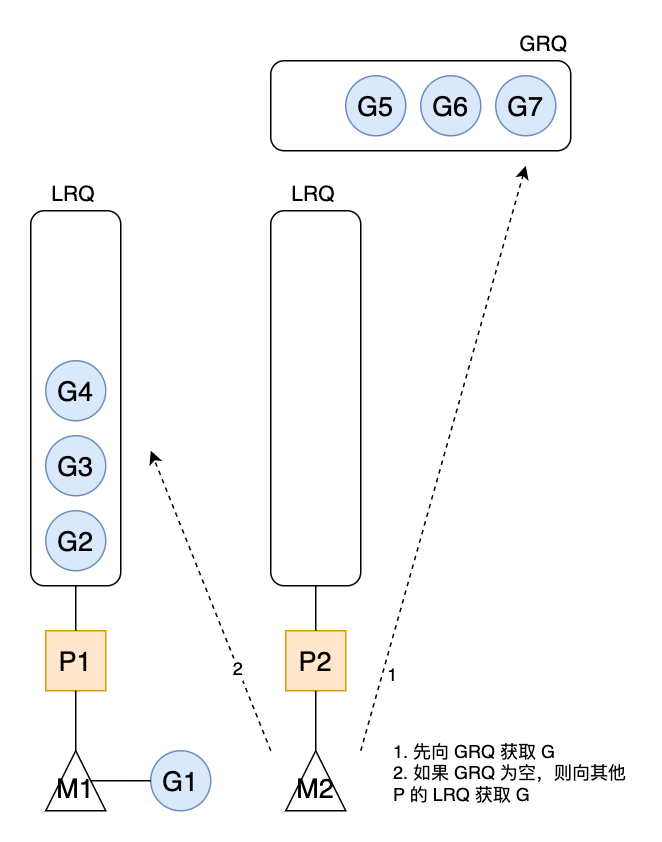
图2 窃取机制
当 M2 从全局队列 GRQ 获取一批 G 放到与之绑定的 P2 的本地队列 LRQ,其拉取的 G 的数量符合下面的公式:
|
|
从公式可以看出,每次至少从全局队列拉取一个 G,但又不会将太多的 G 放到 P 的本地队列,目的是为了给其他 P 留一些。这就是从全局队列到本地队列的负载均衡。
如果全局队列已经没有 G,M2 会执行偷取,从其他 P 的本地队列尾部取一半放到自己的本地队列。
hand over mechanism(交接机制)
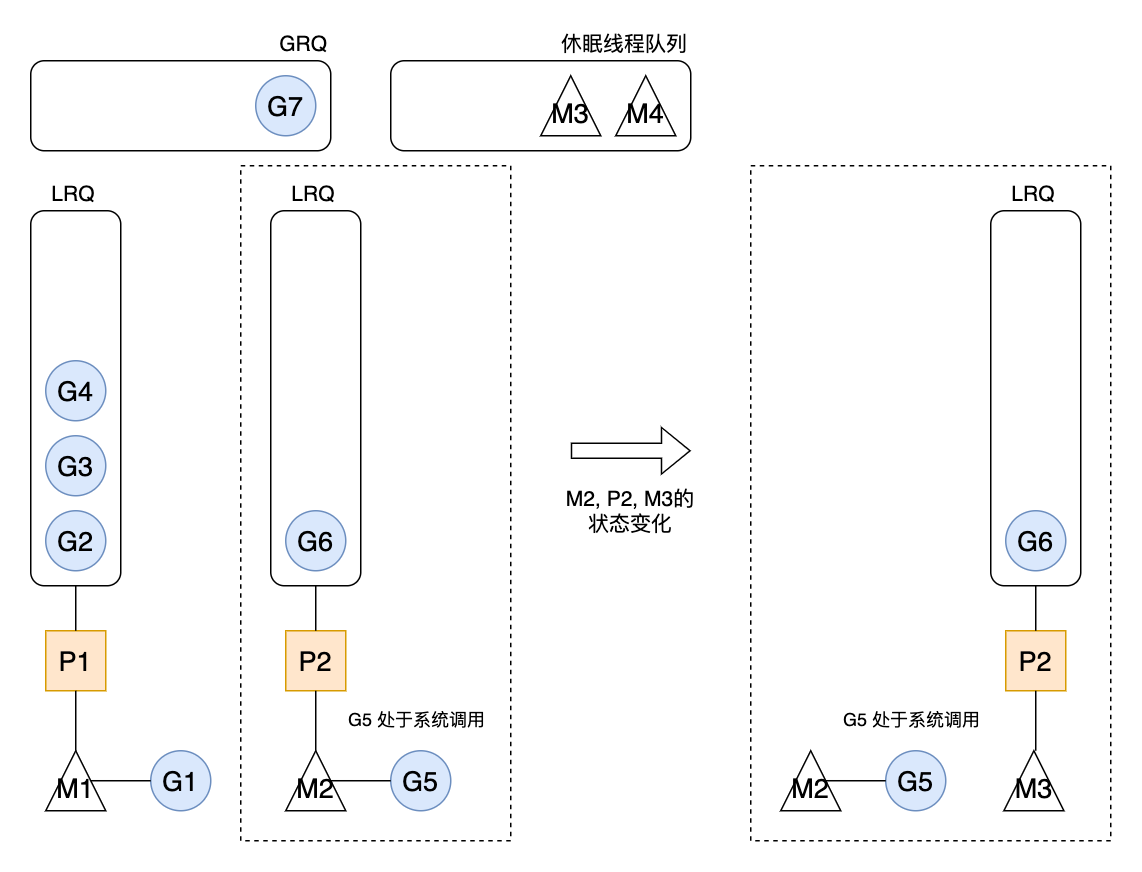
接着讲,如果 M 在执行某个 G 时,G 中因为系统调用而阻塞,导致 M 没有办法继续执行 LRQ 中的 G。那么,M 会主动把与之绑定 P 交接给其他空闲的M,以便 P 中 LRQ 的 G 能够得到执行。
如果没有空闲的 M 可用,调度器会创建新的 M。
这就是为了目标2,尽可能地运行更多的G。
当 G5 因系统调用进入阻塞,那么 M2 和 P2 会立即解绑,P2 会执行以下判断:
|
|
goroutine 和 thread的联系
说到goroutine,不得不提 thread,因为他们很像,但又不同。
这篇文章给了很好的启发,从内存占用,创建和销毁,以及切换时间三个角度来认识两者的不同。
内存占用
创建一个 goroutine 栈内存消耗只有 2KB。实际运行时,可以根据需要在堆内存空间扩缩容。
创建一个 thread 需要消耗 1MB 的栈内存,而且还需要一个称为“guard page"的区域,用于和其他 thread 的栈空间进行隔离。
对于一个用 Go 构建的 HTTP Server 来说,对到来的每个请求,创建一个 goroutine 来处理事非常轻松的事情。但对于一个使用线程作为并发原语的语言构建的服务,每个请求对应一个线程实在是太浪费了,很快就会出现 OOM 错误(OutOfMermonyError)。
创建和销毁
Thread 创建和销毁都有巨大的消耗,因为它直接跟操作系统打交道,是内核级。一般常见的做法是维护一个线程池。
然而,goroutine 是由 runtime 负责,创建和销毁非常容易,消耗特别小,是用户级。
切换成本
Thread 是抢占式调度,在线程切换的时候,调度器必须保存/恢复所有的寄存器。
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
而 goroutine 是协作式调度(cooperatively),当切换发生时,只需要保存/恢复3个寄存器。
Program Counter, Stack Pointer and DX.
所以,goroutine 切换成本要比 thread 小得多。
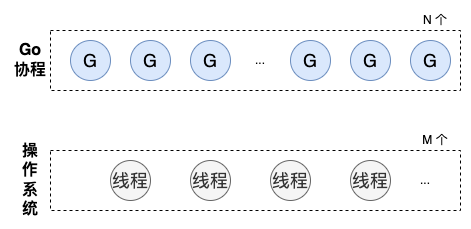
M:N模型
接下来,再解释下什么是M:N模型。
goroutine 是代码层面的并发单位,而 CPU 执行调度的基本单位是线程。
runtime在启动时,创建 M 个系统线程,用户程序在运行中可能创建 N 个goroutine 。N 个协程需要依附在 M 个线程上执行,这就是 M:N模型。
所以,在同一时刻,最多有 M 个goroutine在同时执行。
好了,让我们回到开头的那个问题:为什么一定需要 P 组件呢。
其实在 Go 的早期版本,调度器的模型不是 GMP,而是 GM。调度器维护一个全局等待队列,存放所有的 G,所有的 M 从全局队列中拉取 G 来执行。
这个模型已经在 go 1.1被废弃了,取而代之是当前的 GMP 模型。增加 P 组件,官方给到的原因有两点:
- 在 GM 模型中,M 从全局队列拉取 G,需要加锁。当并发量很大时,上锁/下锁的开销会非常大,严重地限制了 Go 的并发能力。
- 对于 IO 敏感性的任务,如果没有本地队列,当 M 阻塞在 IO 系统调用时,其他 G 没办法得到执行。而 GMP 模型中可以通过 P 将 G 放到其他 M 上执行。
You might wonder now, why have contexts at all? Can’t we just put the runqueues on the threads and get rid of contexts? Not really. The reason we have contexts is so that we can hand them off to other threads if the running thread needs to block for some reason.
An example of when we need to block, is when we call into a syscall. Since a thread cannot both be executing code and be blocked on a syscall, we need to hand off the context so it can keep scheduling.
翻译一下,当一个线程阻塞的时候,将与这个 M 绑定 P 转移到其他线程。
参考资料
- 原文作者:Kevin
- 原文链接:http://www.subond.com/post/2023-07-24_gpm_gpm0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。