[toc]
调度器的初始化
这篇文章,主要引自阿波张公众号「源码游记」的Go语言goroutine调度器初始化,并对照 go 1.20.3 版本的源码进行分析学习,主要包含以下内容:
- 程序如何被系统加载
- 从汇编语言看 go 程序的加载过程
- go 调度器的初始化
任何一个由编译型语言(不管是C,C++,go还是汇编语言)所编写的程序在被操作系统加载起来运行时都会顺序经过如下几个阶段:
- 从磁盘上把可执行程序读入内存;
- 创建进程和主线程;
- 为主线程分配栈空间;
- 把由用户在命令行输入的参数拷贝到主线程的栈;
- 把主线程放入操作系统的运行队列等待被调度执起来运行。
以上引用自阿波张公众号「源码游记」调度器初始化篇,
我们找到rt0_linux_amd64.s文件,这个文件是 go 汇编语言编写的源代码文件。其第 8 行的内容是:
1
2
3
|
// src/runtime/rt0_linux_amd64.s
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
JMP _rt0_amd64(SB)
|
第一行TEXT定义了 _rt0_amd64_linux 这个符号,第二行 JMP 才是真正的指令,也就是主线程的第一条指令。
该指令的意思是跳转到 _rt0_amd64 符号处继续执行,这个符号的定义在src/runtime/asm_amd64.s文件中。
1
2
3
4
5
6
7
8
9
|
// src/runtime/asm_amd64.s#L11
// _rt0_amd64 is common startup code for most amd64 systems when using
// internal linking. This is the entry point for the program from the
// kernel for an ordinary -buildmode=exe program. The stack holds the
// number of arguments and the C-style argv.
TEXT _rt0_amd64(SB),NOSPLIT,$-8
MOVQ 0(SP), DI // argc,用的 MOVQ,即将argc值加载到 DI 上
LEAQ 8(SP), SI // argv,注意用的 LEAQ,即将argv的地址加载到 SI 上
JMP runtime·rt0_go(SB)
|
这是整个程序的启动入口,前两行命令分别是将操作系统传递过来的参数argc和argv数组的地址分别放在 DI 和 SI 寄存器中。
第三行,跳转到runtime.rt0_go 继续执行。
我们继续看runtime.rt0_go的内容:
1
2
3
4
5
6
7
8
|
TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0
// copy arguments forward on an even stack
MOVQ DI, AX // argc, AX = argc
MOVQ SI, BX // argv, BX = &argv
SUBQ $(5*8), SP // 3args 2auto 预留 40个字节
ANDQ $~15, SP // 调整栈顶寄存器,使其按 16 字节对齐
MOVQ AX, 24(SP) // argc 放到 SP + 24 字节处
MOVQ BX, 32(SP) // &argv 放到 SP + 32 字节处
|
先看这条命令SUBQ $(5*8) SP,即 SP = SP - 40,将 SP 指针向下移动 40个字节。
指令AND $~15 SP,即将 15 取反,并于 SP 进行 & 运算。15 的二进制是1111,取反后,变成0000,再跟 SP 相与,相当于把 SP 又变小了,向下移动了 8 个字节。
这样说可能比较难理解,我们画张图就清楚了。
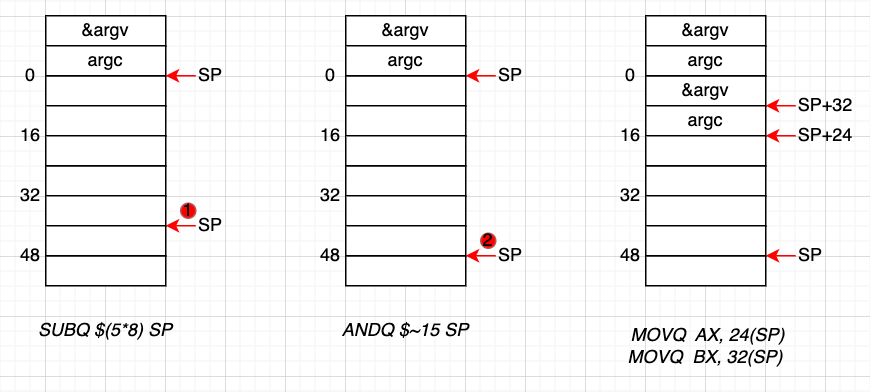
简单总结一下,这几行代码的工作就是在栈顶寄存器上预留一定的空间,并使其按 16 字节对齐,将参数 argv 和 argv搬到新的位置。
至于为什么按 16 字节对齐,是因为 CPU 有一组 SSE 指令,这些指令中出现的内存地址必须是 16 的整数倍。
初始化g0栈空间
好啦,我们接着看后面的代码。
1
2
3
4
5
6
7
8
|
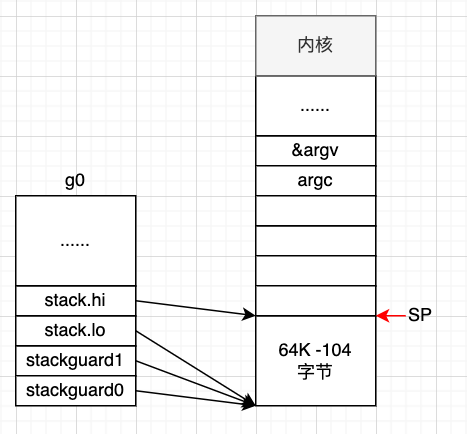
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
MOVQ $runtime·g0(SB), DI // 将g0的地址放入 DI 寄存器
LEAQ (-64*1024+104)(SP), BX // BX = SP - 64K + 104
MOVQ BX, g_stackguard0(DI) // g_stackguard0 = SP - 64K + 104
MOVQ BX, g_stackguard1(DI) // g_stackguard0 = SP - 64K + 104
MOVQ BX, (g_stack+stack_lo)(DI) // g0.stack.lo = SP - 64K + 104
MOVQ SP, (g_stack+stack_hi)(DI) // g0.stack.hi = SP
|
这几行代码就是将 g0 的内存栈进行设定,而且可以看到 g0的内存栈总共大约 64K 字节,地址范围是[SP - 64K + 104, SP]。
执行到这,g0 的栈空间如下:
主线程绑定m0
中间是一些跟 CPU 相关的代码,我们暂时先跳过,直接来到跟 m0 相关的部分:
1
2
3
4
5
6
7
8
9
10
11
|
LEAQ runtime·m0+m_tls(SB), DI // DI = &m0.tls, 即将 m0 tls 成员地址放入 DI 寄存器
CALL runtime·settls(SB) // 调用 settls 设置工作线程 m 的本地存储
// store through it, to make sure it works
// 验证是否可以工作,如果有问题则 abrot 退出程序
get_tls(BX) // 获取 fs 段基地址并放入 BX 寄存器,也就是m0.tls[1]的地址,get_tls 的代码由编译器生成
MOVQ $0x123, g(BX) //
MOVQ runtime·m0+m_tls(SB), AX // AX = m0.tls[0]
CMPQ AX, $0x123
JEQ 2(PC)
CALL runtime·abort(SB)
|
这段代码先是调用settls函数初始化主线程的线程本地存储(TLS),目的是把m0和主线程关联在一起。
【因为 m0 是全局变量,而且 m0 要绑定到工作线程才能执行。】
我们知道,runtime 会启动多个工作线程,每个线程都绑定一个m0。而且,代码还得保持一致,都是用 m0 表示。
这就要用到线程本地存储的知识了,即 TLS (Thread Local Storage),简单来说,TLS 就是线程本地的私有的全局变量。
一般而言,全局变量对进程中多个线程同时可见。
进程中的全局变量与函数内定义的静态变量,是各个线程都可以访问的共享变量。(静态变量放在堆上)
一个线程修改了,其他线程就会“看见“。
要想搞出一个线程私有的变量,就得用到 TLS 技术。
接下来的几行代码是为了验证 TLS 功能是否正常,如果不正常,直接 abort 退出程序。
1
2
3
4
5
6
|
get_tls(BX) // 获取 fs 段基地址并放入 BX 寄存器,也就是m0.tls[0]的地址,get_tls 的代码由编译器生成
MOVQ $0x123, g(BX) // 将常量 0x123 放入 BX 中
MOVQ runtime·m0+m_tls(SB), AX // AX = m0.tls[0]
CMPQ AX, $0x123 // 比较 AX 的值是否与 0x123 相等
JEQ 2(PC) // 相等则跳过第 6 行代码
CALL runtime·abort(SB) // 不想当,直接 abort
|
继续往下看。
1
2
3
4
5
6
7
8
9
10
|
// set the per-goroutine and per-mach "registers"
get_tls(BX)
LEAQ runtime·g0(SB), CX // 将 g0 的地址放入 CX, 即CX = &g0
MOVQ CX, g(BX) // 将 g0 的地址放入线程的本地存储,即 m0.tls[0] = &g0
LEAQ runtime·m0(SB), AX // 将 m0 的地址放入 AX
// save m->g0 = g0
MOVQ CX, m_g0(AX) // m0.g0 = &g0
// save m0 to g0->m
MOVQ AX, g_m(CX) // g0.m = &m0
|
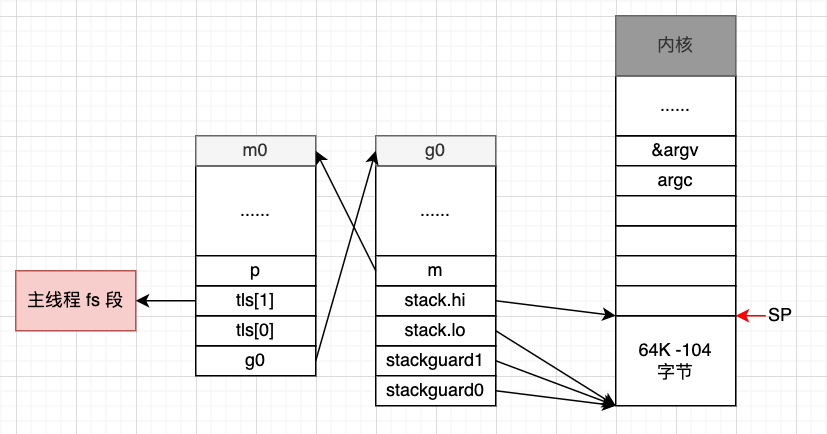
通过这几行代码将 m0 和 g0 进行关联,这个时候,我们可以得到:
1
2
3
|
m0.tls[0] = &g0
m0.g0 = &g0
g0.m = &m0
|
从这里可以看到,保存在主线程本地存储中的值是 g0 的地址,也就是说工作线程的私有全局变量其实是一个指向 g0 的指针,而不是指向 m 的指针。
当前这个指针指向 g0,表示代码正运行在 g0 栈。
还有一点就是,程序的运行其实就是栈空间内容的执行和切换,所以 tls 的值是 g0 的地址,而不是 m 的。
这时候,我们的图就更新成这个样子:
初始化m0
下面就开始初始化 m0了。我们继续看代码:
1
2
3
4
5
6
7
|
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
|
前 4 行通过 MOV 操作将命令行参数放到 SP 的栈顶,紧接着调用runtime.args函数,处理命令行参数。
后面 2 行,连续调用两个 runtime 函数,分别是系统初始化osinit 和 调度器schedint初始化。本文主要关注调度器的初始化,我们重点看schedinit函数。
终于来到了 go 函数,看着顺眼多了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
// src/runtime/proc.go#L677
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
// 前面是一些锁的初始化,可以忽略
......
// 上来先做竞态检查,跟调度器初始化无关,可跳过
gp := getg()
if raceenabled {
gp.racectx, raceprocctx0 = raceinit()
}
// 设置最多启动 10000 个操作系统线程,即 10000 个 M
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
moduledataverify()
stackinit()
mallocinit()
godebug := getGodebugEarly()
initPageTrace(godebug) // must run after mallocinit but before anything allocates
cpuinit(godebug) // must run before alginit
alginit() // maps, hash, fastrand must not be used before this call
fastrandinit() // must run before mcommoninit
mcommoninit(gp.m, -1)
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
stkobjinit() // must run before GC starts
sigsave(&gp.m.sigmask)
initSigmask = gp.m.sigmask
goargs()
goenvs()
parsedebugvars()
gcinit()
// if disableMemoryProfiling is set, update MemProfileRate to 0 to turn off memprofile.
// Note: parsedebugvars may update MemProfileRate, but when disableMemoryProfiling is
// set to true by the linker, it means that nothing is consuming the profile, it is
// safe to set MemProfileRate to 0.
if disableMemoryProfiling {
MemProfileRate = 0
}
lock(&sched.lock)
sched.lastpoll.Store(nanotime())
procs := ncpu // 系统有多少核,就创建多少个P
// 如果存在环境变量GOMAXPROCS,取环境变量的值,创建指定个数的 P
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// procresize 函数具体创建 P
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
// World is effectively started now, as P's can run.
worldStarted()
......
}
|
注意,这段代码有个特殊的函数getg,该函数是由编译器实现的,我们在源码中找不到其定义。这个函数的作用是从线程本地存储中获取当前正在运行的 g。从这里的代码可以看出,当前取出来的是 g0。
除去一些必要的初始化,比较重要的就是mcommoninit函数,该函数对 m0 进行必要的初始化(前面的部分我们已经讲过了,这时 g0.m = &m0)。我们详细看下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
// src/runtime/proc.go#L810
// Pre-allocated ID may be passed as 'id', or omitted by passing -1.
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
// 调度器初始化的时候,传进来的是 -1
// mReserveID函数就是取 sched.mnext 的值,同时检查是否超过 10000 个工作线程的限制
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID() // m0.id = 0
}
lo := uint32(int64Hash(uint64(mp.id), fastrandseed))
hi := uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if lo|hi == 0 {
hi = 1
}
// Same behavior as for 1.17.
// TODO: Simplify ths.
if goarch.BigEndian {
mp.fastrand = uint64(lo)<<32 | uint64(hi)
} else {
mp.fastrand = uint64(hi)<<32 | uint64(lo)
}
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 把 m 挂到全局链表 allm 上
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// Allocate memory to hold a cgo traceback if the cgo call crashes.
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" {
mp.cgoCallers = new(cgoCallers)
}
}
|
从函数的源代码看,这里并没有对 m0 做什么关于调度器的初始化动作,所以可以简单认为这个函数只是把 m0 放入全局链表 allm 中就返回了。
最重要的procresize函数,我们已经分析过了,详见初始化P。这里总结下该函数的主要工作:
- 根据传入的 nproc 参数,创建这么多个 P,要么复用原来的,要么新建
- 初次启动(即初始化),完成 M0 与 P0 的关联
- 检查 allp 列表,将所有空闲的 P 放入全局空闲 P 列表,返回所有可运行的 P 列表
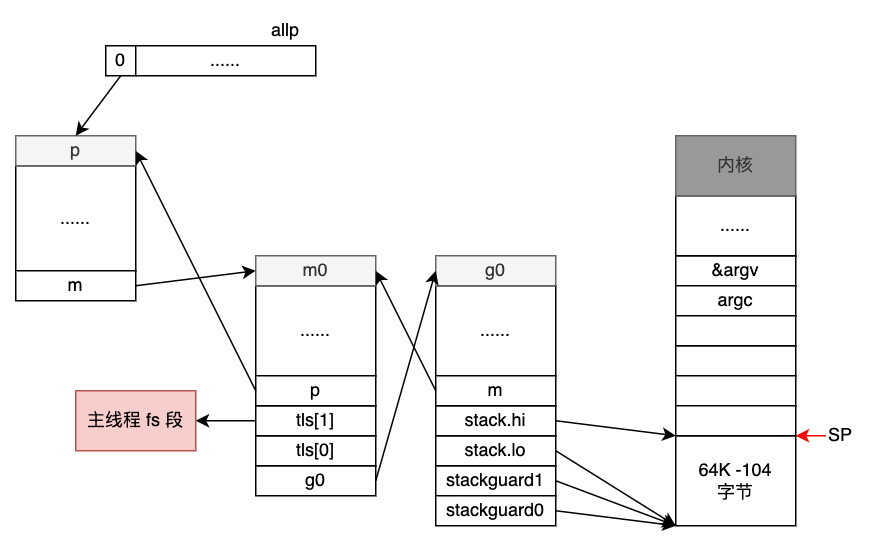
到此,整个schedinit函数执行结束。此时,m0, g0 和 m 所需要的 p 完全关联在一起了。
1
2
|
m0.p = allp[0]
allp[0].m = &m0
|
至此,调度器相关的初始化工作也基本结束了,这个时候整个调度器相关的组成部分之间的关系如下图所示:
参考资料
- https://mp.weixin.qq.com/s/W9D4Sl-6jYfcpczzdPfByQ
- https://golang.design/go-questions/sched/init/