大家好, 我们继续 Go 调度器的旅程。
这篇文章,我们讲讲 GPM 模型中 P 组件内容,主要包含以下方面:
- 为什么需要 P
- P 的结构
- P 的数量
- P 的销毁
- 最重要的 procresize 函数
为什么需要 P
在初始GMP调度器中已经有所提及,我们在回顾一下。
在 Golang 1.1 版本之前调度器中还没有 P 组件,此时调度器的性能还比较差,社区的 Dmitry Vyukov 大佬针对当前调度器中存在的问题进行了总结并设计引入 P 组件来解决当前面临的问题(Scalable Go Scheduler Design Doc),并在 Go 1.1 版本中引入了 P 组件,引入 P 组件后不仅解决了文档中列的几个问题,也引入了一些很好的机制。
文档中列出了调度器主要的 4 个问题,分别有:
-
单一的全局互斥锁。
在以前没有 P 组件的时候,只有 G 和 M 两个组件,以及一个全局 G 队列。当工作线程 M 需要执行 G 的时候,需要频繁地加互斥锁从全局队列中获取 G 来执行,加锁处理对其他 G 的处理(比如创建,完成,调度等)存在很大的时延,性能很差。
-
G 的切换。
M 频繁地切换可运行的 G 会增加延迟和开销。比如新建的 G 会被放入全局队列,而不是在 M 的本地执行,这会导致不必要的开销和延迟,应该优先在创建 G 的 M 上执行。
引入 P 组件之后,新建的 G 会优先放在关联 P 的本地队列中。
-
M 的内存问题。
在以前的版本中,M 结构体中有一个mcache字段,这是一个内存分配池。小对象会直接从mcache中进行分配,因为 G 在 M 上一个一个顺序执行的,G 申请小对象时会直接从mcache中进行分配,G 可以无锁地访问。但是,runtime 中每个时间都只会有一部分的 M 在运行 G,那些处于系统调用的 M 其实是不需要mcache的,这就造成了不必要的浪费。
每个 M 的mcache 大概有 2M 大小的可用内存,当有上千个 G 处于阻塞状态时,就会有大量的内存浪费。
其次,也存在较差的数据局部性问题。这是说 M 运行 G 时对 G 所使用的小对象进行了缓存,当 G 解除阻塞再次调度到同一个 M 时 可以加速访问这些数据,但实际场景中 G 被调度到同一个 M 的概率不高,所以数据局部性不好。
-
频繁的线程阻塞/唤醒问题。
在以前的调度器中,runtime.GOMAXPROCS是限制系统线程的,只有这么多个 M。默认情况下下只有一个系统线程。因为 M 会执行系统调用等操作进入阻塞状态,当 M 阻塞以后不会新建 M 来执行其他任务,而是等待 M 的唤醒,M 在阻塞和唤醒之间频繁切换导致了额外的开销。
引入 P 组件以后,当 M 处于系统调用状态以后,会解除与 P 的关联,调度器会唤醒已有的 M 或者 创建新的 M 来和 P 关联,继续运行 G。
P 的结构
P 对象的数据结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
// src/runtime/runtime2.go#L609
type p struct {
id int32
status uint32 // P 的状态
link puintptr
schedtick uint32 // 被调度的次数,每调度一次递增
syscalltick uint32 // 执行系统调用的次数,每执行一次递增
sysmontick sysmontick // sysmon 最近一次运行的时间
m muintptr // P 所关联的 M,如果 P 为空闲状态,则为 nil
mcache *mcache // 小对象缓存,可以无锁访问
pcache pageCache // 页缓存,也可以无锁访问
raceprocctx uintptr
deferpool []*_defer // pool of available defer structs (see panic.go)
deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
// goroutine ids 缓存
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
// P 的本地可运行队列,LRQ,可无锁方位
// 由 runqhead, runqtail, runq 三者组成的无锁循环队列
// 最多存放 256 个可运行的g
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
//
// Note that while other P's may atomically CAS this to zero,
// only the owner P can CAS it to a valid G.
// 待运行的 g
// 如果不为空,且当前时间片还有时间的话,优先运行runnext
// 其他 P 可以将其设置为 0,但只有自身的P 可以将其设置为非零
runnext guintptr
// Available G's (status == Gdead)
// 已结束运行的 G
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
// Cache of mspan objects from the heap.
// 来自堆上的 mspan 缓存
mspancache struct {
// We need an explicit length here because this field is used
// in allocation codepaths where write barriers are not allowed,
// and eliminating the write barrier/keeping it eliminated from
// slice updates is tricky, moreso than just managing the length
// ourselves.
len int
buf [128]*mspan
}
// gc 相关字段
gcMarkWorkerMode gcMarkWorkerMode
gcMarkWorkerStartTime int64
gcw gcWork
......
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
// 抢占标记
preempt bool
}
|
有了基本的认识,我们对 P 结构体中的几个关键字段,详细说明下:
runnext指向的是 g 指针,表示当前 P (进入_Prunning)立即要运行的 g,可能为nil。
如果此字段不为nil的话,将直接从runnext字段取,而不比从 runq 中取,所以其优先级高于runq。
这个字段是用来实现调度器的亲和性。我们知道一个 g 阻塞时,m 会从 p 的本地队列 或者 全局队列 再获取一个 g 来执行。如果原来的 g 执行阻塞结束,想再次被接着执行,就需要重新在 p 的 runq 进行排队,当runq 中有太多的 g 要执行时,导致这个刚刚被解除阻塞的 g 迟迟无法得到执行,同时还有可能被其他 m 窃取(因为窃取是从尾部开始偷)。从 Go 1.5 开始,得益于 P 的特殊属性,从阻塞 channel 返回的 g 会优先执行,此时只需要将这个 g 放在 runnext上即可。
本地可运行队列LRQ
runqhead,可运行队列的队头runqtail,可运行队列的队尾runq,可运行队列,最大256
这三个字段组成了一个无锁的循环队列,即 P 的本地可运行队列。
M 每次查找工作时,就是从这里找可运行的 g。
P 的数量
在【初始GPM模型】中已经提到过,P 的数量由用户决定,程序启动时环境变量$GOMAXPROCS或者 runtime 的GOMAXPROCS()方法决定。这意味着在程序的整个生命周期都最多只有$GOMAXPROCS个 G 在同时运行。
P 的销毁
如果在整个 Go 程序的运行时没有调整GOMAXPROCS,P 的数量就是不变的,所以不存在销毁。但是未使用的 P 会放到调度器的sched.pidle队列中,等有需要的时候,再从里面取出。
如果调小了GOMAXPROCS,那么会通过p.destroy()函数将多余的 P 关联的资源回收,并且将 P 设置为_Pdead状态,此时可能还有与 P 关联的 M,所以 P 对象不会回收。
扩展
有一篇博客提到了如何缩小它。
P 的状态
P 总共有五种状态,各自定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// src/runtime/runtime2.go#L106
const (
// P status
// _Pidle means a P is not being used to run user code or the
// scheduler. Typically, it's on the idle P list and available
// to the scheduler, but it may just be transitioning between
// other states.
//
// The P is owned by the idle list or by whatever is
// transitioning its state. Its run queue is empty.
_Pidle = iota
// _Prunning means a P is owned by an M and is being used to
// run user code or the scheduler. Only the M that owns this P
// is allowed to change the P's status from _Prunning. The M
// may transition the P to _Pidle (if it has no more work to
// do), _Psyscall (when entering a syscall), or _Pgcstop (to
// halt for the GC). The M may also hand ownership of the P
// off directly to another M (e.g., to schedule a locked G).
_Prunning
// _Psyscall means a P is not running user code. It has
// affinity to an M in a syscall but is not owned by it and
// may be stolen by another M. This is similar to _Pidle but
// uses lightweight transitions and maintains M affinity.
//
// Leaving _Psyscall must be done with a CAS, either to steal
// or retake the P. Note that there's an ABA hazard: even if
// an M successfully CASes its original P back to _Prunning
// after a syscall, it must understand the P may have been
// used by another M in the interim.
_Psyscall
// _Pgcstop means a P is halted for STW and owned by the M
// that stopped the world. The M that stopped the world
// continues to use its P, even in _Pgcstop. Transitioning
// from _Prunning to _Pgcstop causes an M to release its P and
// park.
//
// The P retains its run queue and startTheWorld will restart
// the scheduler on Ps with non-empty run queues.
_Pgcstop
// _Pdead means a P is no longer used (GOMAXPROCS shrank). We
// reuse Ps if GOMAXPROCS increases. A dead P is mostly
// stripped of its resources, though a few things remain
// (e.g., trace buffers).
_Pdead
)
|
翻译一下:
| 状态 |
描述 |
_Pidel |
没有运行任何代码,或者被调度器调度到,此时 P 的 LRQ 为空 |
_Prunning |
P 被 M 绑定,且运行用户代码或者调度器代码。只有绑定的 M 才可以改变_Prunning状态。M 可以修改 P 的状态为_Pidle(无工作可做)、_Psyscall(系统调用)、_Pgcstop(GC);另外 M 也可以将 P 的使用权交给另一个 M (调度一个锁定状态的 G) |
_Psyscall |
当 G 被执行进入系统调用,P 会被关联的 M 设置为该状态 |
_Pgcstop |
当程序运行过程中发生 GC 时,P 会被关联的 M 设为该状态 |
_Pdead |
运行时如果将GOMAXPROCS调小,会将多余的 P 设置为该状态 |
【状态转移图】
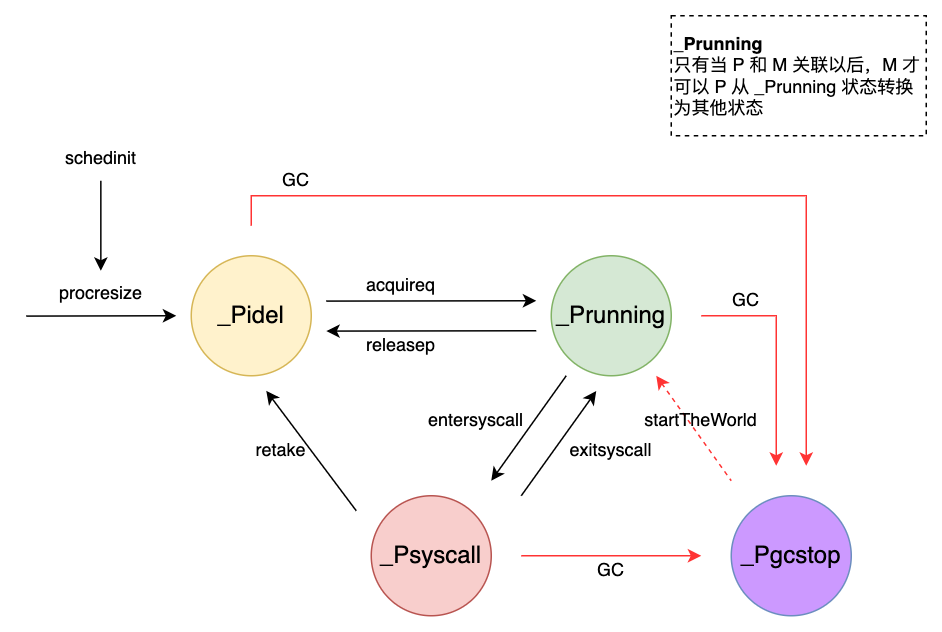
在M如何找工作中,我们已经详细分析了acquireq函数和releasep函数,今天我们看下最主要的procresize函数,即 P 是如何被创建的。其他函数我们会在后续的篇章中逐一讲到。
P 的初始化
P 是在程序最开始的时候由调度器进行初始化,通过函数procresize实现,该函数在schedinit中被调用。
其源码如下:
1
2
3
4
5
6
7
8
9
10
11
|
// src/runtime/proc.go#L740 这段代码在 schedinit() 函数内部
lock(&sched.lock)
sched.lastpoll.Store(nanotime())
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
|
这里先设置 procs,它决定了 P 的数量。ncpu 已经在前面被赋上了系统的核心数,所以代码里不设置环境变量 GOMAXPROCS 也没问题,如果设置了,则取环境变量值。
我们继续往下看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
|
// src/runtime/proc.go#L4937
// 入参:需要创建的 P 的个数
// 出参:P 的列表
func procresize(nprocs int32) *p {
// 环境检查,确保已经上锁,确保worldstop
assertLockHeld(&sched.lock)
assertWorldStopped()
// 参数检查,程序启动时 gomaxprocs为0
old := gomaxprocs
if old < 0 || nprocs <= 0 {
throw("procresize: invalid arg")
}
if trace.enabled {
traceGomaxprocs(nprocs)
}
// update statistics
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
maskWords := (nprocs + 31) / 32
// Grow allp if necessary.
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
// 如果需要的 P 个数小于 allp 的容量,缩小 allp 容量
allp = allp[:nprocs]
} else {
// 否则,创建临时 nallp 数组,并 allp 全部拷贝至 nallp
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
// 更新 allp
allp = nallp
}
// 以上将 allp 调整到需要的大小,即 nproc
// .....
}
// initialize new P's
// 初始化 P, 初次启动时,old为0
for i := old; i < nprocs; i++ {
pp := allp[i]
// 申请新 P 对象
if pp == nil {
pp = new(p)
}
// 初始化 P,每个 P 都有一个ID,该ID就是 P 在 allp 的索引
pp.init(i)
// 将 P 放入 allp 中
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
// 以上,初始化了所有 p 对象,存放在 allp 数组中
// 获取当前正在运行的 g,初始化时后,这里就是g0
// 初始化时,g0所在的 p 还是0,所以会进入 else 逻辑
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
// continue to use the current P
// 继续使用当前的 P
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
// 初始化会进到这个分支,
// ......
// 将 g0 所在 p 清空
gp.m.p = 0
// 取第 0 号 p,清空m, 并设置p状态为 _Pidle
pp := allp[0]
pp.m = 0
pp.status = _Pidle
// acquirep() 函数将 m0/p0 关联起来
acquirep(pp)
}
// g.m.p is now set, so we no longer need mcache0 for bootstrapping.
// 此时 m0,g0 已经设置,不在需要mcache0
mcache0 = nil
// release resources from unused P's
// 释放不在使用的 P 的资源,但不会收回 P,因为有可能处于系统调用的M还会关联 P
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
// 如果 allp 超过了 nprocs 进行缩容,一般运行时不调整 nprocs 所以不进入这个逻辑
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
idlepMask = idlepMask[:maskWords]
timerpMask = timerpMask[:maskWords]
unlock(&allpLock)
}
// 下面这个 for 循环检查 allp,将 空闲的P 放入全局空闲P列表;
// 如果 P 的 LRQ 不为空,即有工作可做,将这些可运行的 P 链起来
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
// allp[0] 已经跟 m0 关联了,所以要跳过
if gp.m.p.ptr() == pp {
continue
}
// 将状态转为 _Pidle
pp.status = _Pidle
// 如果 P 的 LRQ 为空,将其加入 全局空闲P列表
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
if old != nprocs {
// Notify the limiter that the amount of procs has changed.
gcCPULimiter.resetCapacity(now, nprocs)
}
// 返回所有可运行的 P 列表
return runnablePs
}
|
总结一下,procresize函数主要做了以下工作:
- 根据传入的 nproc 参数,创建这么多 P,要么复用原来的P,要么新建
- 初次启动时,该函数完成了 M0 与 P0 的关联
- 检查 allp 列表,将所有空闲的 P 放入全局空闲 P 列表,返回所有可运行的 P 列表
这里面有一个关键函数acquirep,即关联 P 和 M,需要详细看一下:
1
2
3
4
5
6
7
8
9
10
|
// src/runtime/proc.go#L5088
// Associate p and the current m.
// 关联 P 到当前的 M
func acquirep(pp *p) {
// wirep 执行真正的关联
wirep(pp)
// 整理mcache
pp.mcache.prepareForSweep()
// ......
}
|
可以看到,执行关联的是wirep函数,继续往下看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// src/runtime/proc.go
func wirep(pp *p) {
gp := getg()
if gp.m.p != 0 {
throw("wirep: already in go")
}
if pp.m != 0 || pp.status != _Pidle {
id := int64(0)
if pp.m != 0 {
id = pp.m.ptr().id
}
print("wirep: p->m=", pp.m, "(", id, ") p->status=", pp.status, "\n")
throw("wirep: invalid p state")
}
// 将 P / M 相互引用,并设置 P 为 _Prunning
gp.m.p.set(pp)
pp.m.set(gp.m)
pp.status = _Prunning
}
|
到此,procresize函数就分析结束了。从调度器的初始化来说,工作已经完成了。
这里引用下阿波张公众号的文章对该函数的总结,很简洁清楚。
- 使用 make([]*p, nprocs) 初始化全局变量 allp,即 allp = make([]*p, nprocs)
- 循环创建并初始化 nprocs 个 p 结构体对象并依次保存在 allp 切片之中
- 把 m0 和 allp[0] 绑定在一起,即 m0.p = allp[0],allp[0].m = m0
- 把除了 allp[0] 之外的所有 p 放入到全局变量 sched 的 pidle 空闲队列之中
关于第四点特别说明下,从代码看,对于非空闲的 P,该函数将其生成一个链表,并返回给调用者。
但实际上,schedinit函数对procresize的调用并没有关心其结果,如下:
1
2
3
4
|
// src/runtime/proc.go
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
|
所以,初始化的时候,procresize 就是将除 allp[0] 之外的所有 P 都放入了全局空闲 P 列表。
其他说明
通过上面对 go 1.20.3 版本源码的分析,做进一步的说明。
- 参考资料 2 中,作者所使用的源码是
go 1.9.2,新建的 P 的初始状态为_Pgcstop状态,但是在go 1.20.3版本中,新建的 P 初始状态为_Pidle。
参考资料
- https://blog.tianfeiyu.com/2021/12/12/golang_gpm/
- https://golang.design/go-questions/sched/init/