本文源码基于 go 1.20.3 版本,如有问题,欢迎指出。
更新时间:2023.08.11
首次发布:2023.08.07
M 的结构
M 是 OS 线程的实体,我们看几个比较重要的字段,包括:
- 用于执行调度的g0
- 用于信号处理的gsignal
- 线程本地存储tls
- 当前正在运行的curg
- 执行 Goroutine 时需要的本地资源p(如果没有执行,则为nil)
- 执行系统调用前上一次绑定的oldp【结束系统调用的时候,优化恢复上一次绑定的p】
- 表示自身状态的spinning
等等其他五十多个字段,包括关于 M 的调度信息、调试信息等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// src/runtime/runtime2.go
type m struct {
g0 *g // g0主要用来记录工作线程使用的栈信息,在执行调度代码时使用g0
gsignal *g // 用于信号处理的g
tls [tlsSlots]uintptr // 工作线程本地存储
curg *g // 当前正在运行的 g,即用户创建的可运行的 g 放在这里执行
p puintptr // 执行Goroutine代码时绑定的p(如果没有执行,则为nil)
nextp puintptr // 【当 m 被唤醒时,首先绑定这个p】
oldp puintptr // G进入系统调用前上一次绑定的p
spinning bool // 自旋标志位(当 m 没有work 且 处于寻找 work 的状态)
incgo bool // m 正在执行 cgo 调用
// 没有 g 需要运行时,工作线程休眠在这个 park 成员上
// 当有工作需要做时,其他工作线程通过 park 字段唤醒该工作线程
park note
alllink *m // 在 allm 上
freelink *m // 在 sched.freem 上
...
}
|
M 的创建
有两种场景需要创建 M:
- Go 程序启动时会创建主线程,主线程的第一个 M,即M0
- 当有新 G 创建,或者有可运行的 G,且还有空闲的 P,那么会调用
starm函数。startm函数会从 全局空闲M 队列取一个 M,和空闲的 P 绑定,执行G,如果没有空闲的M,就会通过newm创建一个。
M 的销毁
M 不会被销毁,但当 M 找不到工作或者找不到空闲的 P 时,会通过stopm进入休眠状态。那么,什么情况下会进入休眠状态呢?
有两种情况:
第一种:没有工作可做。
当 M 绑定的 P 没有可运行的 G 且 无法从其他 P 和 全局可运行 G 列表找到可运行的G 时,M 会尝试进入自旋状态。注意,进入自旋状态的M数量有限制,处于自旋状态的M数量最多为非空闲P的数量一半。
如果 M 在自旋状态没有找到可运行的 G 或者 未能进入自旋状态,就会直接进入休眠状态。【详见下面 M 如何工作部分。】
第二种:没有空闲的P。
当 M 执行的 G,进入系统调用,M 会主动与绑定的 P 解绑,当 G 退出系统调用时,M 会找一个空闲的 P 进行绑定,进而继续执行 G,但是如果找不到空闲的 P,此时 M 也会调用stopm进入休眠。
stopm函数会将休眠的 M 放入全局的空闲队列(sched.midle),等待其他工作线程唤醒 M 时,从列表中取。
M 的运行
M 需要与 P 绑定才能运行,且 M 与 P 有亲和性。
当 M 执行的 G 进入系统调用,M 与 P 会进行解绑,M 会将当前的 P 记录到 m.oldp 中;当 G 退出系统调用时,M 会尝试优先绑定 m.oldp 中的 P。
M 的状态
通过前面的分析,可以知道 M 有三种状态:运行,自旋、休眠,其关系如下:
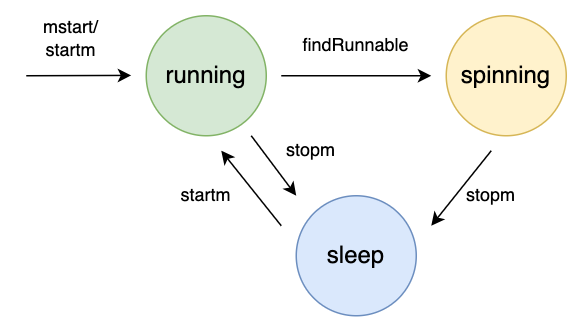
有些文章,将 M 的状态分为自旋和非自旋,主要从m.spinning来考虑。但笔者认为分成三种状态更易于理解,非自旋状态下,M 要么工作,要么休眠。
- 自旋状态:当 M 没有工作,且努力找工作的时候,就是自旋
- 运行状态:M 有工作处理
- 休眠状态:M 没有工作可做,或者无法进入自旋,就会进入休眠状态
M 如何找工作
下面,我们围绕 M 的状态,结合源码,分析下 M 是如何工作的。
我们知道 M 的职责就是找到一个可运行的 G,然后执行它。从大方向来讲,主要有三个过程:
- 先从本队队列中找
- 定期从全局队列中找
- 最后去别的 P 上偷
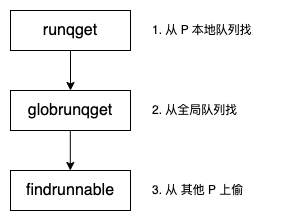
先看第一个过程,从 P 的本地队列找。源码分析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// src/runtime/proc.go
// 从本队队列寻找一个可运行的 g
// 如果 inheritTime 为真,则 gp 应该继承当前时间片的剩余时间,否则新开一个时间片
// 只有绑定的 p可执行该函数
func runqget(pp *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
// 如果 runext 不为空,那么 runnext 就是下一个可运行的g
next := pp.runnext
// If the runnext is non-0 and the CAS fails, it could only have been stolen by another P,
// because other Ps can race to set runnext to 0, but only the current P can set it to non-0.
// Hence, there's no need to retry this CAS if it fails.
// 如果 runnext 不为空,且 cas 失败,那么 runnext 只能是被其他p偷走了
// 因为其他 p 可以将 runnext 置为零,但只有当前 p 可以将其置为非零。
// 所以,当 cas 失败后,没有必要进行重试。
if next != 0 && pp.runnext.cas(next, 0) {
// 如果找到 runnext,则返回 runnext 所指向的指针,且继承时间片
return next.ptr(), true
}
for {
// 取本地队列的队头
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
// 取队尾
t := pp.runqtail
if t == h {
// 头尾相同,说明本地队列为空,找不到g
return nil, false
}
// 取队头的g
gp := pp.runq[h%uint32(len(pp.runq))].ptr()
// 原子操作,防止这中间被其他线程因偷工作而修改
if atomic.CasRel(&pp.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
|
整个代码还是比较简单,主要是两部分。
第一部分,先尝试获取 runnext,因为它的运行优先级更高。因为其他工作线程“偷工作”也是优先查看 runnext,所以这里用了原子操作。
第二部分,从本地队列中找。如果头尾相等,说明队列为空,直接返回。否则,取队头所指向的 g,并通过原子操作将队头指向下一个。原子操作同样为了避免其他工作线程因为“偷工作”而修改队头。
我们再来看第二个过程,从全局队列中获取 goroutine。需要说明的是,globrunqget函数的三次调用都在findRunnable函数中,其条件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// src/runtime/proc.go
// 第一次调用
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
// 为了公平,每调用 schedule 函数 61 次,才会从全局队列中获取 g
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 每次最多获取 1 个 goroutine
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
|
这说明,并不是每次调度都会从全局队列中获取可运行的 g。实际情况是调度器每调度 61 次,且全局队列有可运行的 g 时,才会调用globrunqget函数从全局队列中获取。因为,从全局队列中获取需要上锁,开销有些大,能不做就不做。
其次,每次获取最多获取 1 个可运行的 g,这是为了保证从其他工作线程也能从全局队列中获取到可运行的 g。
好了,我们仔细看下 globrunqget 函数的内容。
该函数的第一个参数就是当前工作线程所绑定的 P,第二个参数max表示最多可从全局队列中取多少个 G 放到当前 P 的本地队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// src/runtime/proc.go
// Try get a batch of G's from the global runnable queue.
// sched.lock must be held.
// 尝试从全局队列中获取可运行的 g,必须上下锁。
// 最多获取 max 个,如果 max 为零,则不限制个数。
func globrunqget(pp *p, max int32) *g {
assertLockHeld(&sched.lock)
// 如果全局队列为空,直接返回
if sched.runqsize == 0 {
return nil
}
// 计算可供获取的个数 n
// 全局队列中的个数/P的个数,加1,保证最少能获取 1 个
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
// 如果 max 有效,且可供获取的个数大于 max,取 max 个
if max > 0 && n > max {
n = max
}
// 最多获取 P 本地队列的一半,为了保证其他工作线程也能够获取到
if n > int32(len(pp.runq))/2 {
n = int32(len(pp.runq)) / 2
}
sched.runqsize -= n
// 直接通过函数返回gp,其他的g通过runqput放入本地队列
gp := sched.runq.pop()
n--
for ; n > 0; n-- {
// 继续去队头,并放入 p 的本地队列
gp1 := sched.runq.pop()
runqput(pp, gp1, false)
}
// 返回队头所指向的 goroutine
return gp
}
|
代码还是比较好理解的。
先根据全局队列可运行 g 的长度和 P 的个数,计算可供获取的 g 的个数,获得一个结果。
然后根据参数 max 和 P 的本地可运行队列的长度一半,修正上述结果。
最后,从全局队列中取,放入 P 的本地队列。
把全局队列中可运行的 g 转移到 P 的本地队列,保证了全局队列中可运行 g 的执行机会。这是从全局队列到本地队列的负载均衡。
知识点:
M 从 全局队列取的 G 的数据符合下面这个公式。
1
|
n = min(len(GRQ)/GOMAXPROCS + 1, len(LRQ)/2)
|
最后,我们看下第三个过程,从其他 P 中 “偷工作”。findRunnable函数只在调度函数schedule中出现。
这个函数有点长,我们一点点看。先看返回参数有三个:
- gp,即可运行的 goroutine,这是寻找的目标
- inheritTime,同上面介绍的一样,即是否需要继承时间片
- tryWakeP,表示 g 所在的 P 需要被唤醒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
|
// src/runtime/proc.go
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
// tryWakeP indicates that the returned goroutine is not normal (GC worker, trace
// reader) so the caller should try to wake a P.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
// 当前 g 所在的 m
mp := getg().m
// The conditions here and in handoffp must agree: if
// findrunnable would return a G to run, handoffp must start
// an M.
top:
// 还记得吗?m 结构中的 p 表示 m 执行go代码时所绑定的p
pp := mp.p.ptr()
if sched.gcwaiting.Load() {
gcstopm()
goto top
}
if pp.runSafePointFn != 0 {
runSafePointFn()
}
// now and pollUntil are saved for work stealing later,
// which may steal timers. It's important that between now
// and then, nothing blocks, so these numbers remain mostly
// relevant.
now, pollUntil, _ := checkTimers(pp, 0)
// Try to schedule the trace reader.
if trace.enabled || trace.shutdown {
gp := traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
return gp, false, true
}
}
// Try to schedule a GC worker.
// 尝试调度 gc 工作线程,如果找到可运行的gc线程,返回gc线程
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
// 这里前面介绍了,为了保证公平,定期地检查全局队列
// 一定是调度 61 次 且 全局队列不为空,才会调用globrunqget,
// 而且最多从全局队列中拿 1 个
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// Wake up the finalizer G.
if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// local runq
// 从 p 的本地队列中寻找,如果找到,直接返回
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// global runq
// 这里是,只要全局队列不为空,就从全局队列中拿,且不限制个数
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// Poll network.
// This netpoll is only an optimization before we resort to stealing.
// We can safely skip it if there are no waiters or a thread is blocked
// in netpoll already. If there is any kind of logical race with that
// blocked thread (e.g. it has already returned from netpoll, but does
// not set lastpoll yet), this thread will do blocking netpoll below
// anyway.
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}
// Spinning Ms: steal work from other Ps.
//
// Limit the number of spinning Ms to half the number of busy Ps.
// This is necessary to prevent excessive CPU consumption when
// GOMAXPROCS>>1 but the program parallelism is low.
// 如果 m 为自旋状态,或者 自旋m数小于忙碌的p个数一半
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {
if !mp.spinning {
mp.becomeSpinning()
}
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
// 成功"偷到工作“,那么直接返回
return gp, inheritTime, false
}
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
// wasm only:
// If a callback returned and no other goroutine is awake,
// then wake event handler goroutine which pauses execution
// until a callback was triggered.
gp, otherReady := beforeIdle(now, pollUntil)
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
if otherReady {
goto top
}
// Before we drop our P, make a snapshot of the allp slice,
// which can change underfoot once we no longer block
// safe-points. We don't need to snapshot the contents because
// everything up to cap(allp) is immutable.
allpSnapshot := allp
// Also snapshot masks. Value changes are OK, but we can't allow
// len to change out from under us.
idlepMaskSnapshot := idlepMask
timerpMaskSnapshot := timerpMask
// return P and block
lock(&sched.lock)
if sched.gcwaiting.Load() || pp.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
if sched.runqsize != 0 {
gp := globrunqget(pp, 0)
unlock(&sched.lock)
return gp, false, false
}
if !mp.spinning && sched.needspinning.Load() == 1 {
// See "Delicate dance" comment below.
mp.becomeSpinning()
unlock(&sched.lock)
goto top
}
// 当前工作线程解除与 p 的绑定关系,准备去休眠
if releasep() != pp {
throw("findrunnable: wrong p")
}
// 将 p 放入空闲队列
now = pidleput(pp, now)
unlock(&sched.lock)
// Delicate dance: thread transitions from spinning to non-spinning
// state, potentially concurrently with submission of new work. We must
// drop nmspinning first and then check all sources again (with
// #StoreLoad memory barrier in between). If we do it the other way
// around, another thread can submit work after we've checked all
// sources but before we drop nmspinning; as a result nobody will
// unpark a thread to run the work.
//
// This applies to the following sources of work:
//
// * Goroutines added to a per-P run queue.
// * New/modified-earlier timers on a per-P timer heap.
// * Idle-priority GC work (barring golang.org/issue/19112).
//
// If we discover new work below, we need to restore m.spinning as a
// signal for resetspinning to unpark a new worker thread (because
// there can be more than one starving goroutine).
//
// However, if after discovering new work we also observe no idle Ps
// (either here or in resetspinning), we have a problem. We may be
// racing with a non-spinning M in the block above, having found no
// work and preparing to release its P and park. Allowing that P to go
// idle will result in loss of work conservation (idle P while there is
// runnable work). This could result in complete deadlock in the
// unlikely event that we discover new work (from netpoll) right as we
// are racing with _all_ other Ps going idle.
//
// We use sched.needspinning to synchronize with non-spinning Ms going
// idle. If needspinning is set when they are about to drop their P,
// they abort the drop and instead become a new spinning M on our
// behalf. If we are not racing and the system is truly fully loaded
// then no spinning threads are required, and the next thread to
// naturally become spinning will clear the flag.
//
// Also see "Worker thread parking/unparking" comment at the top of the
// file.
wasSpinning := mp.spinning
// 如果自旋状态下实在没有工作做,那么置为 非自旋,全局自旋m数减一
if mp.spinning {
mp.spinning = false
if sched.nmspinning.Add(-1) < 0 {
throw("findrunnable: negative nmspinning")
}
// Note the for correctness, only the last M transitioning from
// spinning to non-spinning must perform these rechecks to
// ensure no missed work. However, the runtime has some cases
// of transient increments of nmspinning that are decremented
// without going through this path, so we must be conservative
// and perform the check on all spinning Ms.
//
// See https://go.dev/issue/43997.
// Check all runqueues once again.
// 休眠之前,为了确保没有错过工作要做,当 m 从自旋状态进入非自旋状态,再次检查一遍所有的p
// 如果发现有工作要做,回到自旋状态,重新寻找
pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
goto top
}
// Check for idle-priority GC work again.
// 如果找到空闲的 gc 工作,则运行 gc 工作
pp, gp := checkIdleGCNoP()
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
// Run the idle worker.
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
// Finally, check for timer creation or expiry concurrently with
// transitioning from spinning to non-spinning.
//
// Note that we cannot use checkTimers here because it calls
// adjusttimers which may need to allocate memory, and that isn't
// allowed when we don't have an active P.
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)
}
// Poll network until next timer.
if netpollinited() && (netpollWaiters.Load() > 0 || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 {
sched.pollUntil.Store(pollUntil)
if mp.p != 0 {
throw("findrunnable: netpoll with p")
}
if mp.spinning {
throw("findrunnable: netpoll with spinning")
}
// Refresh now.
now = nanotime()
delay := int64(-1)
if pollUntil != 0 {
delay = pollUntil - now
if delay < 0 {
delay = 0
}
}
if faketime != 0 {
// When using fake time, just poll.
delay = 0
}
list := netpoll(delay) // block until new work is available
sched.pollUntil.Store(0)
sched.lastpoll.Store(now)
if faketime != 0 && list.empty() {
// Using fake time and nothing is ready; stop M.
// When all M's stop, checkdead will call timejump.
stopm()
goto top
}
lock(&sched.lock)
pp, _ := pidleget(now)
unlock(&sched.lock)
if pp == nil {
injectglist(&list)
} else {
acquirep(pp)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
if wasSpinning {
mp.becomeSpinning()
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := sched.pollUntil.Load()
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
// m 进入休眠状态
stopm()
goto top
}
|
这部分最能说明 M 找工作的精神:尽力从本地队列 或 全局队列中寻找工作,如果实在找不到再进入休眠状态,等待有工作时,被其他 M 唤醒。
另外,阅读这部分源码需要注意每个return的部分。先看前两个。
第一个地方,如果找到 traceReader,则直接trace工作。这说明 trace 优先级最高。
第二个地方,检查 gc 工作,如果有,则执行 gc 工作。
紧接着,先周期性地检查全局队列。
然后,先从 p 本地队列找寻找 goroutine,如果找不到,再去全局队列中寻找;实在找不到,就只能去”偷“了。
为了避免 GOMAXPROCS很大,但程序并发很小情况下,过多的 m 进入自旋状态,所以限制了 自旋状态的个数,不超过 忙碌 P 的一半。
如果成功”偷“到了,那么执行偷来的工作。
如果没有偷到呢?如果没偷到,依然有工作可以做。
如果当前正处在 gc 的标记阶段,那么安全地扫描和标记对象,所以依然有工作可以做。看看人家这是什么精神。
如果依然没有工作要做,在放弃 P 之前,对所有的 P 做一次快照。
然后,才释放P,将其放入空闲队列。
如果 M 是自旋状态,那么再次检查所有的可运行队列,检查「空闲优先级」的 gc 工作。
如果没有工作可做,才会 stopm。
整个过程的流程图如下。
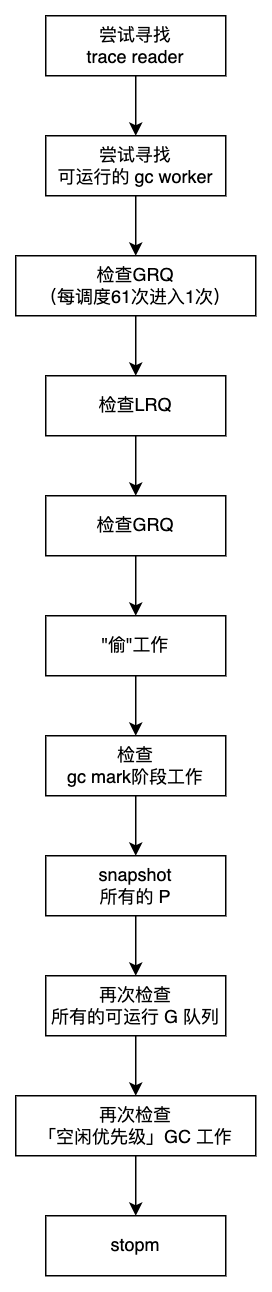
这个过程涉及三个关键点,分别是”怎么偷“,”解除 P 与 M 的关联“,以及“进入休眠”。
怎么偷
我们看下stealWork函数的源码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
// src/runtime/proc.go
// stealWork attempts to steal a runnable goroutine or timer from any P.
// 尝试从任何一个 P 中偷一个可运行的 G 或者 时间
// If newWork is true, new work may have been readied.
//
// If now is not 0 it is the current time. stealWork returns the passed time or
// the current time if now was passed as 0.
// 尝试从任何一个 P 中偷一个可运行的 G 或者 时间.
// 如果 newWork 为真,表示有可运行的 G.
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
pp := getg().m.p.ptr()
ranTimer := false
const stealTries = 4
for i := 0; i < stealTries; i++ {
stealTimersOrRunNextG := i == stealTries-1
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting.Load() {
// GC work may be available.
return nil, false, now, pollUntil, true
}
p2 := allp[enum.position()]
if pp == p2 {
continue
}
// Steal timers from p2. This call to checkTimers is the only place
// where we might hold a lock on a different P's timers. We do this
// once on the last pass before checking runnext because stealing
// from the other P's runnext should be the last resort, so if there
// are timers to steal do that first.
//
// We only check timers on one of the stealing iterations because
// the time stored in now doesn't change in this loop and checking
// the timers for each P more than once with the same value of now
// is probably a waste of time.
//
// timerpMask tells us whether the P may have timers at all. If it
// can't, no need to check at all.
if stealTimersOrRunNextG && timerpMask.read(enum.position()) {
tnow, w, ran := checkTimers(p2, now)
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
if ran {
// Running the timers may have
// made an arbitrary number of G's
// ready and added them to this P's
// local run queue. That invalidates
// the assumption of runqsteal
// that it always has room to add
// stolen G's. So check now if there
// is a local G to run.
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, now, pollUntil, ranTimer
}
ranTimer = true
}
}
// Don't bother to attempt to steal if p2 is idle.
if !idlepMask.read(enum.position()) {
if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {
return gp, false, now, pollUntil, ranTimer
}
}
}
}
// No goroutines found to steal. Regardless, running a timer may have
// made some goroutine ready that we missed. Indicate the next timer to
// wait for.
return nil, false, now, pollUntil, ranTimer
}
|
从函数可以看到这样几点:
- 最多尝试偷4次,即第一个 for 循环
- 从其他 P “偷工作”也是通过
runqget函数,只不过传入的参数为其他 P
解除 P 与 M 的关联
当实在没有工作可做是,就会解除与 P 的绑定,我们看下releasep函数,解除绑定都做了啥。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// src/runtime/proc.go
// Disassociate p and the current m.
func releasep() *p {
gp := getg()
if gp.m.p == 0 {
throw("releasep: invalid arg")
}
pp := gp.m.p.ptr()
if pp.m.ptr() != gp.m || pp.status != _Prunning {
print("releasep: m=", gp.m, " m->p=", gp.m.p.ptr(), " p->m=", hex(pp.m), " p->status=", pp.status, "\n")
throw("releasep: invalid p state")
}
if trace.enabled {
traceProcStop(gp.m.p.ptr())
}
// 将各自的引用都置为零
gp.m.p = 0
pp.m = 0
pp.status = _Pidle // 将 P 标记为 Pidle 状态
return pp
}
|
前面都是一些合法性校验,主要工作就是将 M/P 互相引用的字段清空,并将 P 的状态置为_Pidle。
一旦释放P,P 变为空闲状态,进而会放入全局的空闲列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// src/runtime/proc.go
// 将 P 放到 空闲列表
func pidleput(pp *p, now int64) int64 {
assertLockHeld(&sched.lock)
if !runqempty(pp) {
throw("pidleput: P has non-empty run queue")
}
if now == 0 {
now = nanotime()
}
updateTimerPMask(pp) // clear if there are no timers.
idlepMask.set(pp.id)
// 将 p.link 指向 sched.pidle所指向的 p,也就是空闲列表的第一个p
pp.link = sched.pidle
// 更新 sched.pidle
sched.pidle.set(pp)
// 全局空闲 p 数量加1
sched.npidle.Add(1)
if !pp.limiterEvent.start(limiterEventIdle, now) {
throw("must be able to track idle limiter event")
}
return now
}
|
所有的空闲 p 以链表的方式存储。整个构造过程是,先讲 p.link 指向 sched.pidle(表头)所指向的 p,然后在更新 sched.pidle,使其指向当前 p,这样链表就构造完成了。
进入休眠
接下来,要进入休眠了,这部分主要是stopm函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// 休眠,要停止执行工作,
// src/routime/proc.go
// 停止执行工作,直到有新的工作可做为止。
func stopm() {
gp := getg()
if gp.m.locks != 0 {
throw("stopm holding locks")
}
if gp.m.p != 0 {
throw("stopm holding p")
}
if gp.m.spinning {
throw("stopm spinning")
}
// 上锁,将 m 放到全局空闲队列中,下锁
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
// m 进入休眠
mPark()
// 将 m 与 nextp 关联起来,前面讲过,m 被唤醒后,首先绑定nextp,所以这里关联一下
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
|
mPark里面就两个函数,notesleep函数使当前工作线程进入休眠状态。其他工作线程在检测到“当前有很多工作要做”,会调用noteclear将其唤醒。
1
2
3
4
5
|
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}
|
还记得 park 字段吗?它是一个note,结构很简单只有一个key字段。
1
2
3
|
type note struct {
key uintptr
}
|
note 的底层实现机制跟操作系统相关,不同系统使用不同的机制,比如 linux 下使用的 futex 系统调用,而 mac 下则是使用的 pthread_cond_t 条件变量,note 对这些底层机制做了一个抽象和封装。
这种封装给扩展性带来了很大的好处,比如当睡眠和唤醒功能需要支持新平台时,只需要在 note 层增加对特定平台的支持即可,不需要修改上层的任何代码。
上面这一段来自阿波张的系列教程。我们接着来看下 notesleep 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// src/runtime/lock_sema.go
func notesleep(n *note) {
gp := getg()
if gp != gp.m.g0 {
throw("notesleep not on g0")
}
semacreate(gp.m)
if !atomic.Casuintptr(&n.key, 0, uintptr(unsafe.Pointer(gp.m))) {
// Must be locked (got wakeup).
if n.key != locked {
throw("notesleep - waitm out of sync")
}
return
}
// Queued. Sleep.
// 入队了,开始休眠
// 表示 m 被阻塞了
gp.m.blocked = true
// 注意这里分了两种
if *cgo_yield == nil { // 如果 cgo 调用为空,-1 表示无限期休眠
semasleep(-1)
} else {
// Sleep for an arbitrary-but-moderate interval to poll libc interceptors.
// 这里之所以需要用一个循环,是因为 futexsleep 有可能意外从睡眠中返回,
// 所以 futexsleep 函数返回后还需要检查 note.key 是否还是 0,
// 如果是 0 则表示并不是其它工作线程唤醒了我们,
// 只是 futexsleep 意外返回了,需要再次调用 futexsleep 进入睡眠
const ns = 10e6
for atomic.Loaduintptr(&n.key) == 0 {
semasleep(ns)
asmcgocall(*cgo_yield, nil)
}
}
// 一旦,note.key 不为 0,表示其他工作线程唤醒了我们,
// 将 阻塞 放开
gp.m.blocked = false
}
|
我们继续看下noteclear,负责将 note.key 置零。
1
2
3
4
5
6
7
8
9
10
11
|
// src/runtime/proc.go
// One-time notifications.
func noteclear(n *note) {
if GOOS == "aix" {
// On AIX, semaphores might not synchronize the memory in some
// rare cases. See issue #30189.
atomic.Storeuintptr(&n.key, 0)
} else {
n.key = 0
}
}
|
至此,找不到工作的 M 就休眠了。当其他工作线程发现有工作要做时,就会找到空闲的 M,再通过 m.park 字段唤醒本线程。
唤醒之后,回到findRunnable函数,继续寻找 g,找到后返回 schedule 函数,然后去执行找到的 g。
这就是 M 找工作的过程,真不简单呀。
startm
最后,再看下startm函数,这是启动 M 的过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
// src/runtime/proc.go
// 调度 M 运行 P,必要时可以创建 M。
// Schedules some M to run the p (creates an M if necessary).
// If p==nil, tries to get an idle P, if no idle P's does nothing.
// May run with m.p==nil, so write barriers are not allowed.
// If spinning is set, the caller has incremented nmspinning and must provide a
// P. startm will set m.spinning in the newly started M.
// 如果 spinning 被设置,说明调用者递增了 自旋M 数,而且必须提供 P,所以这个情况 P 不能为空。
//
// Callers passing a non-nil P must call from a non-preemptible context. See
// comment on acquirem below.
//
// Must not have write barriers because this may be called without a P.
//
//go:nowritebarrierrec
func startm(pp *p, spinning bool) {
// 取一个 M
mp := acquirem()
lock(&sched.lock)
if pp == nil {
if spinning {
// TODO(prattmic): All remaining calls to this function
// with _p_ == nil could be cleaned up to find a P
// before calling startm.
throw("startm: P required for spinning=true")
}
// 从空闲列表中取一个 P
pp, _ = pidleget(0)
// 如果没取到 P,啥也不做,直接返回。
if pp == nil {
unlock(&sched.lock)
releasem(mp)
return
}
}
// 到这里,已经找到 P 了
// 从全局空闲M列表中取一个 M
nmp := mget()
if nmp == nil {
// No M is available, we must drop sched.lock and call newm.
// However, we already own a P to assign to the M.
//
// Once sched.lock is released, another G (e.g., in a syscall),
// could find no idle P while checkdead finds a runnable G but
// no running M's because this new M hasn't started yet, thus
// throwing in an apparent deadlock.
//
// Avoid this situation by pre-allocating the ID for the new M,
// thus marking it as 'running' before we drop sched.lock. This
// new M will eventually run the scheduler to execute any
// queued G's.
// 翻译过来:如果没有 M 可用,其他 G 也发现这种情况,尝试创建 M,但这个 M 还没有创建出来
// 为了避免这种情况,通过 ID 来解决
id := mReserveID()
unlock(&sched.lock)
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
// 用 自旋函数 创建一个 M
newm(fn, pp, id)
// Ownership transfer of pp committed by start in newm.
// Preemption is now safe.
releasem(mp)
return
}
// 从全局空闲M列表取到一个M
unlock(&sched.lock)
if nmp.spinning {
throw("startm: m is spinning")
}
if nmp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(pp) {
throw("startm: p has runnable gs")
}
// The caller incremented nmspinning, so set m.spinning in the new M.
// 设置 M 的自旋状态
nmp.spinning = spinning
// 将 P 设为 M 唤醒后优先绑定的P
nmp.nextp.set(pp)
// 通过 park 唤醒 M
notewakeup(&nmp.park)
// Ownership transfer of pp committed by wakeup. Preemption is now
// safe.
releasem(mp)
}
|
总结一下:
startm首先检查有没有空闲的 P 可以绑定,如果没有,啥也不做,直接返回;- 如果找到空闲的 P,再从空闲 M 列表找,如果没有空闲的 M,就会创建一个,然后返回。
- 否则,将找到的空闲的 P 设置为 M 的 nextp,并将 M 唤醒。
M0 的创建
我们再看下 mstart()。
1
2
3
|
// mstart is the entry-point for new Ms.
// It is written in assembly, uses ABI0, is marked TOPFRAME, and calls mstart0.
func mstart()
|
这是 M 创建的入口,是用汇编写的,标记为TOPFRAME。
所以,Go 程序启动的时候,会先进到这里。
继续,看下mstart0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
// mstart0 is the Go entry-point for new Ms.
func mstart0() {
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
// Initialize stack bounds from system stack.
// Cgo may have left stack size in stack.hi.
// minit may update the stack bounds.
//
// Note: these bounds may not be very accurate.
// We set hi to &size, but there are things above
// it. The 1024 is supposed to compensate this,
// but is somewhat arbitrary.
size := gp.stack.hi
if size == 0 {
size = 8192 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
// Initialize stack guard so that we can start calling regular
// Go code.
gp.stackguard0 = gp.stack.lo + _StackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
gp.stackguard1 = gp.stackguard0
mstart1()
// Exit this thread.
if mStackIsSystemAllocated() {
// Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in gp.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
mexit(osStack)
}
// The go:noinline is to guarantee the getcallerpc/getcallersp below are safe,
// so that we can set up g0.sched to return to the call of mstart1 above.
//
//go:noinline
func mstart1() {
gp := getg()
if gp != gp.m.g0 {
throw("bad runtime·mstart")
}
// Set up m.g0.sched as a label returning to just
// after the mstart1 call in mstart0 above, for use by goexit0 and mcall.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
// And goexit0 does a gogo that needs to return from mstart1
// and let mstart0 exit the thread.
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
// Install signal handlers; after minit so that minit can
// prepare the thread to be able to handle the signals.
// 启动 M0
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 开始调度
schedule()
}
|
M0 的作用
如前所述,M0 是go runtime 创建的第一个系统线程(即主线程),一个 Go 进程只有一个 M0。
从「数据结构」看,M0 跟其他 M 没有区别,都是m结构。
从「创建」看,M0 是一个全局变量,在 src/runtime/proc.go 定义,M0 不需要在堆上分配内存,其他 M 都是通过 new(m) 创建出来的对象,其内存是从堆上进行分配的。
另外,从mstart代码看,M0 是进程在启动时由汇编创建的,而其他 M 都是go runtime创建的。
从「作用」看,M0 负责执行初始化操作和启动第一个 G,Golang 程序启动时会首先启动 M0,M0 和主线程进行了绑定,当 M0 启动第一个 G 即 main goroutine 后功能就和其他的 M 一样了 。
其他函数分析
关于 M,还有几个函数没有分析,我们也依次看下。
第一个函数是runqput,该函数将可运行的 G 放到 P 的本地队列。
runqput
该函数的第一个参数pp,表示当前绑定的P,第二个参数g,表示可运行的G,第三个参数next,true表示将 g 放入p.runnext,否则放入p.runq队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// src/runtime/proc.go#L5957
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the pp.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(pp *p, gp *g, next bool) {
if randomizeScheduler && next && fastrandn(2) == 0 {
next = false
}
if next {
retryNext:
oldnext := pp.runnext
// 如果没有放入成功,继续尝试
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
// 放入成功,且之前为0,表示当前绑定的 P,已经将runnext设置完成,直接返回
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
// 否则,将其原来的 runnetx 放到普通的LRQ
gp = oldnext.ptr()
}
retry:
// 取 LRQ 队头
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
// 取 LRQ 队尾
t := pp.runqtail
// 如果 LRQ 队列未满,直接放入队尾,且队尾向后移动一个
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// LRQ 队列满了,runqputslow 负责将LRQ中 1/2 的 g 放入GRQ
if runqputslow(pp, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
// LRQ 未满,继续尝试存放
goto retry
}
|
总结一下:
runnext具备高优先级,通过next开关控制放入runnext还是runq- 由 p 中的runq, runqhead, runqtail组成的无锁循环队列,存放可运行的g
- 如果存放过程中 LRQ 队列满了,则将部分 g 放入 GRQ
runqput将新加入的 g 放到了队尾
接着,继续看下runqputslow函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// src/runtime/proc.go#L5995
// Put g and a batch of work from local runnable queue on global queue.
// Executed only by the owner P.
func runqputslow(pp *p, gp *g, h, t uint32) bool {
var batch [len(pp.runq)/2 + 1]*g
// First, grab a batch from local queue.
// 取 LRQ 队列中一半的g
n := t - h
n = n / 2
if n != uint32(len(pp.runq)/2) {
throw("runqputslow: queue is not full")
}
// 将一半的 g 放入临时 batch 数组
for i := uint32(0); i < n; i++ {
batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr()
}
if !atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return false
}
batch[n] = gp
// 如果随机调度开关打开,将 batch 数组随机一下
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// Link the goroutines.
// 将 g 链接起来
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
// 放入临时 gQueue 队列
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
// 放入 临时队列 放入 GRQ
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true
}
|
总结一下,runqputslow就是将 LRQ 队列中靠近头的一半 g 放入 GRQ,如果随机调度打开,将 g 的顺序随机打乱一次。
内容回顾
参考资料
- https://golang.design/under-the-hood/zh-cn/part2runtime/ch06sched/mpg/
- https://studygolang.com/articles/28706
- https://golang.design/go-questions/sched/m-worker/
- https://blog.tianfeiyu.com/2021/12/12/golang_gpm/
- https://mp.weixin.qq.com/s/2objs5JrlnKnwFbF4a2z2g